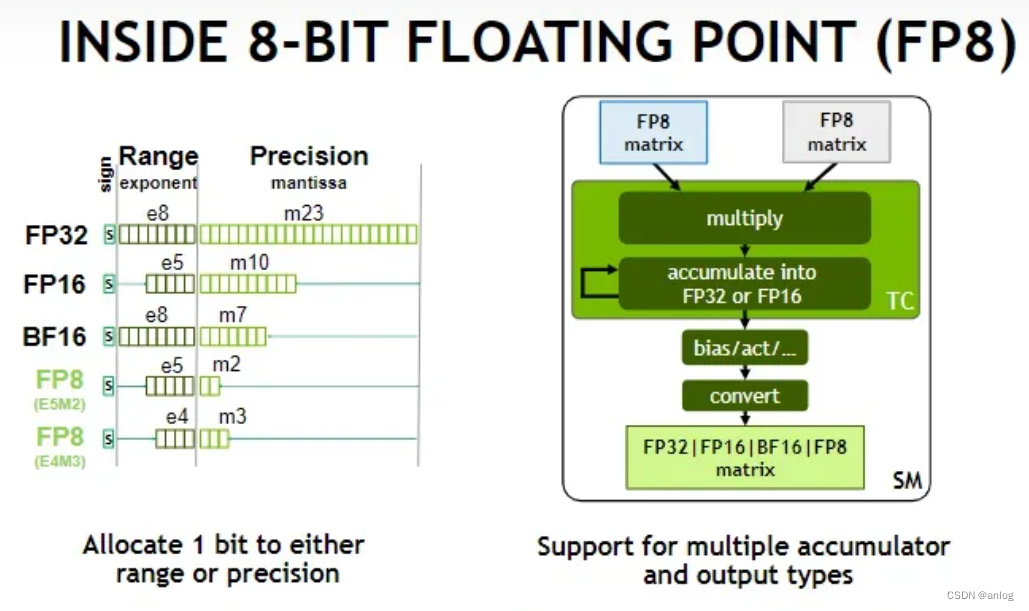
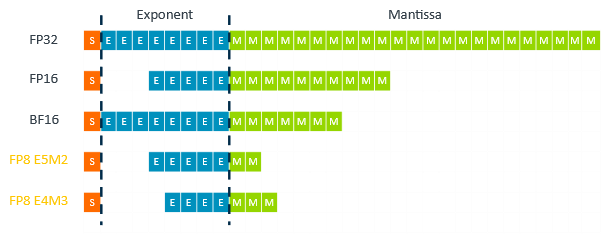
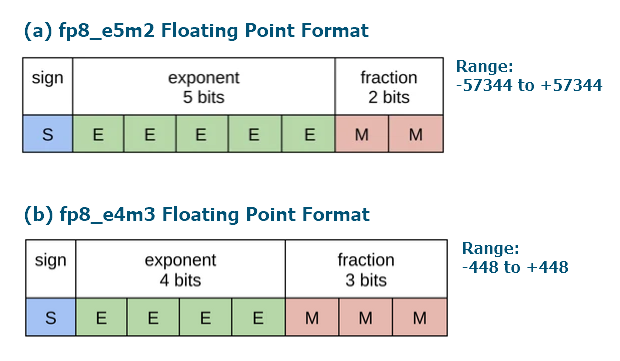
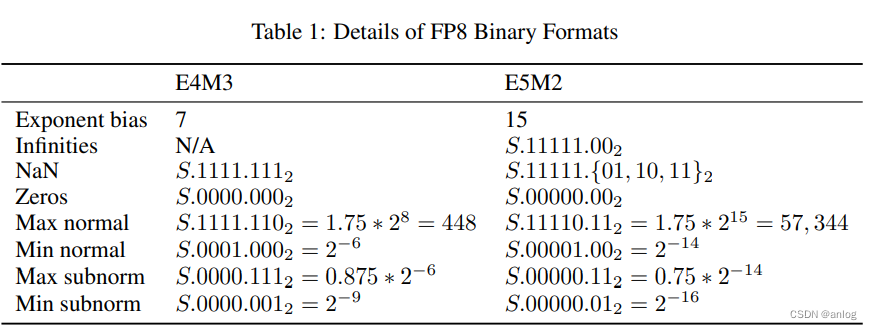
Showing 109 of 109on this page. Filters & sort apply to loaded results; URL updates for sharing.109 of 109 on this page
NVIDIA, Arm, and Intel Collaborate To Push FP8 Format Standard For Deep ...
FP8 Format | Standardized Specification for AI - Jotrin Electronics
Using FP8 and FP4 with Transformer Engine — Transformer Engine 2.13.0 ...
DeepSeek V3.1 发布,更令人好奇的是UE8M0 FP8
深度学习中的 FP8 格式详解 - Py学习
FP8 训练的挑战及最佳实践 - 超擎数智
FP8 数据格式在大型模型训练中的应用、挑战及最佳实践 - 知乎
[Intel Gaudi] #4. FP8 Quantization - SqueezeBits
Using FP8 with Transformer Engine — Transformer Engine 2.0.0 documentation
FP8 训练的挑战及最佳实践 - 知乎
Accelerating Llama3 FP8 Inference with Triton Kernels – PyTorch
FP8 训练的挑战和最佳实践_NVIDIA AI 技术专区-NVIDIA AI 技术专区
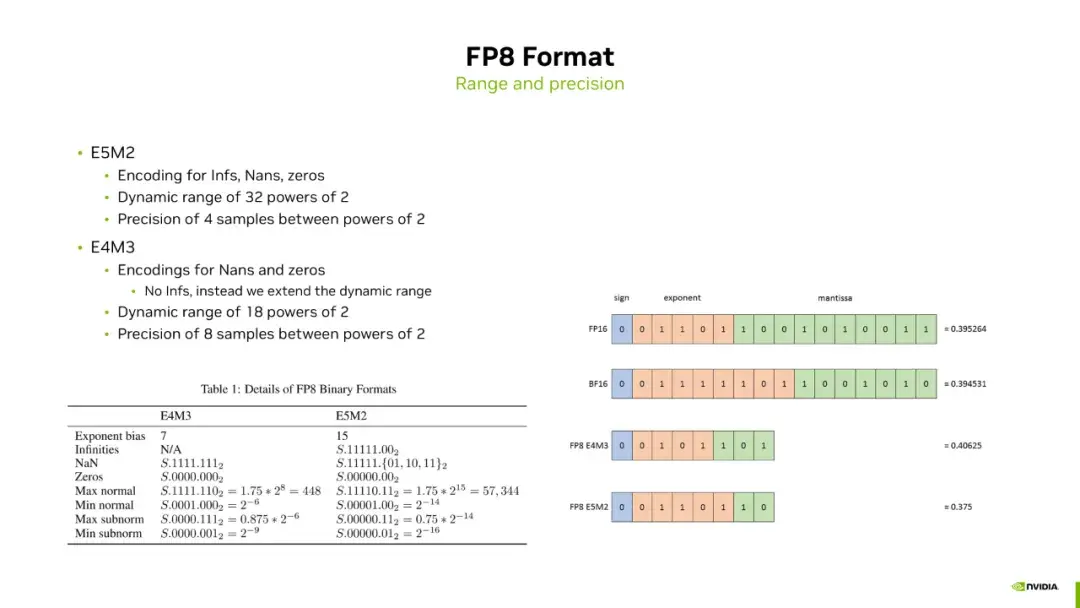
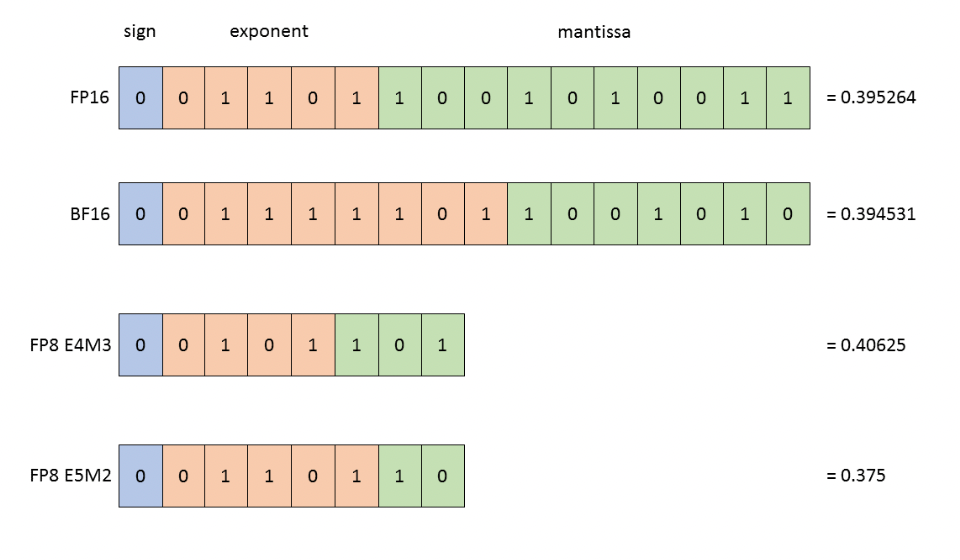
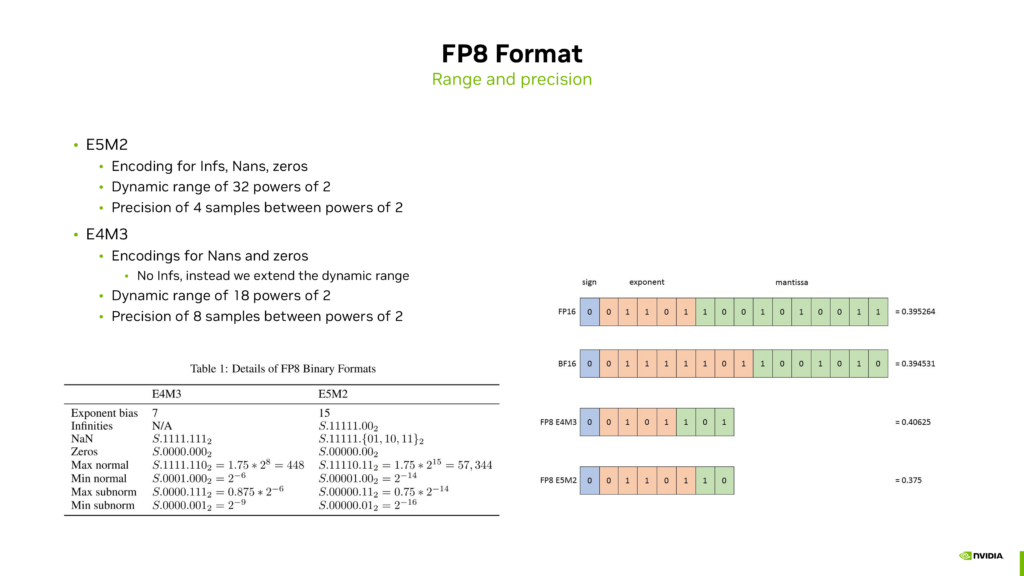
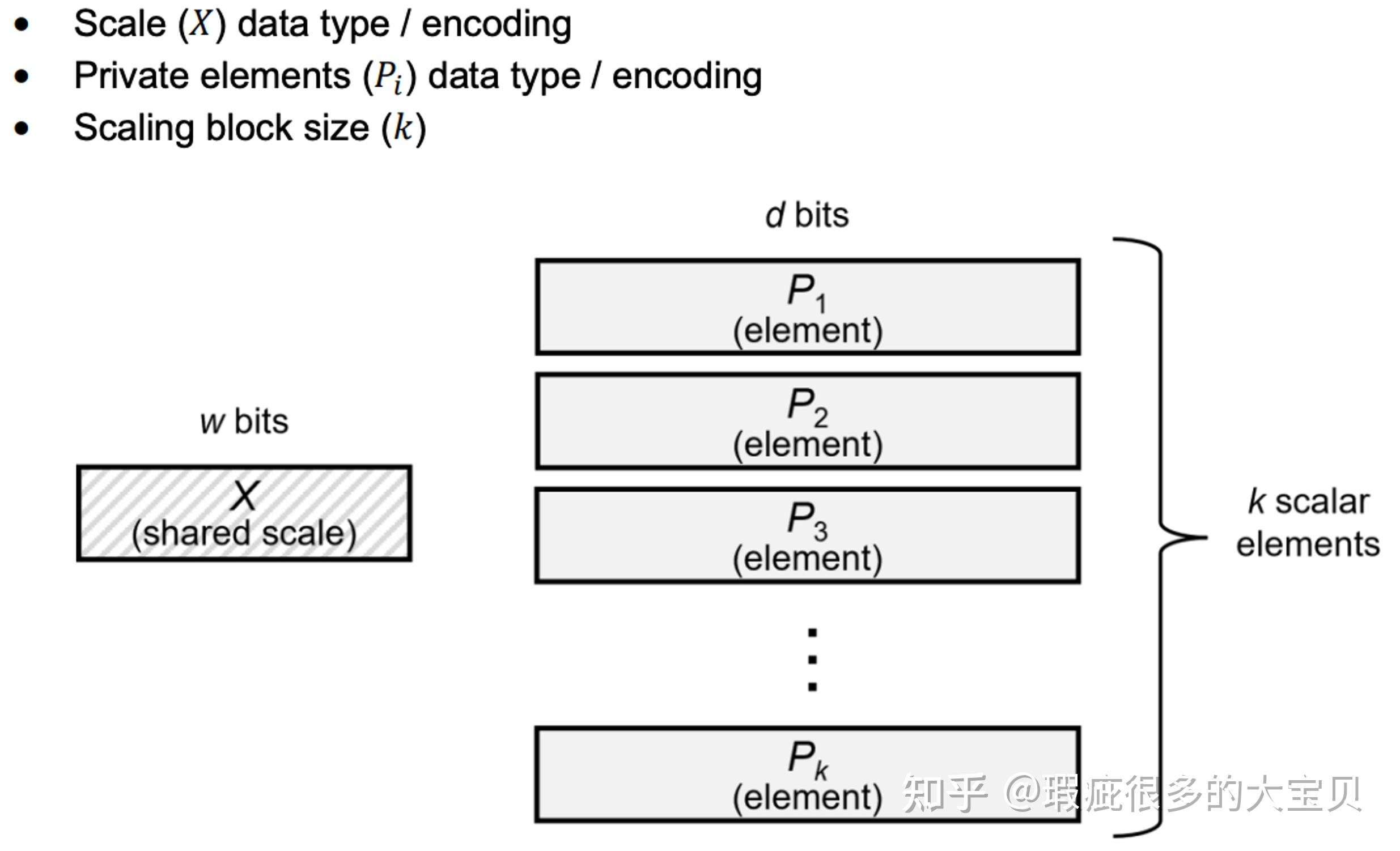
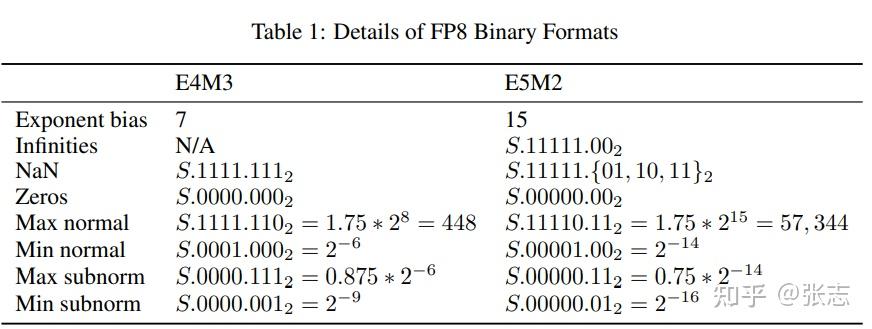
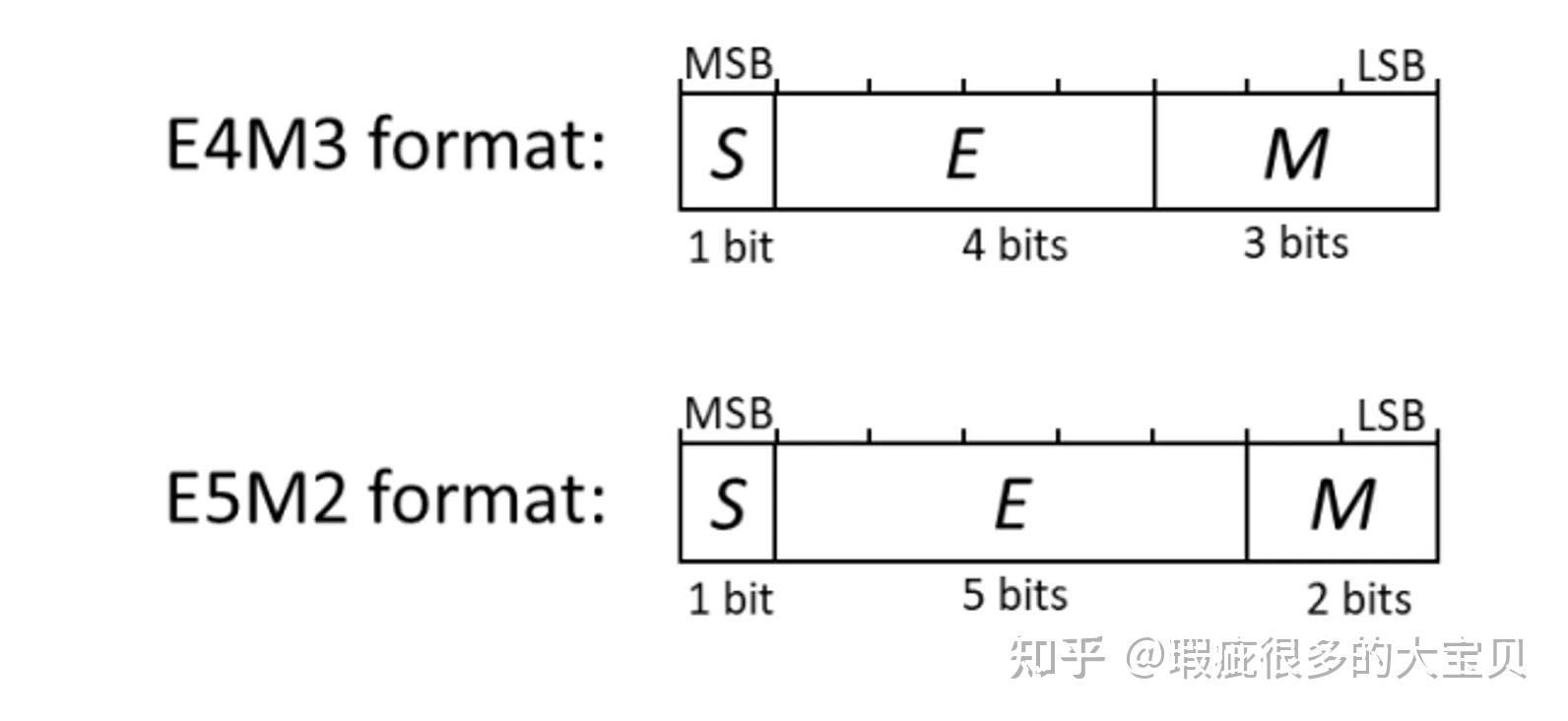
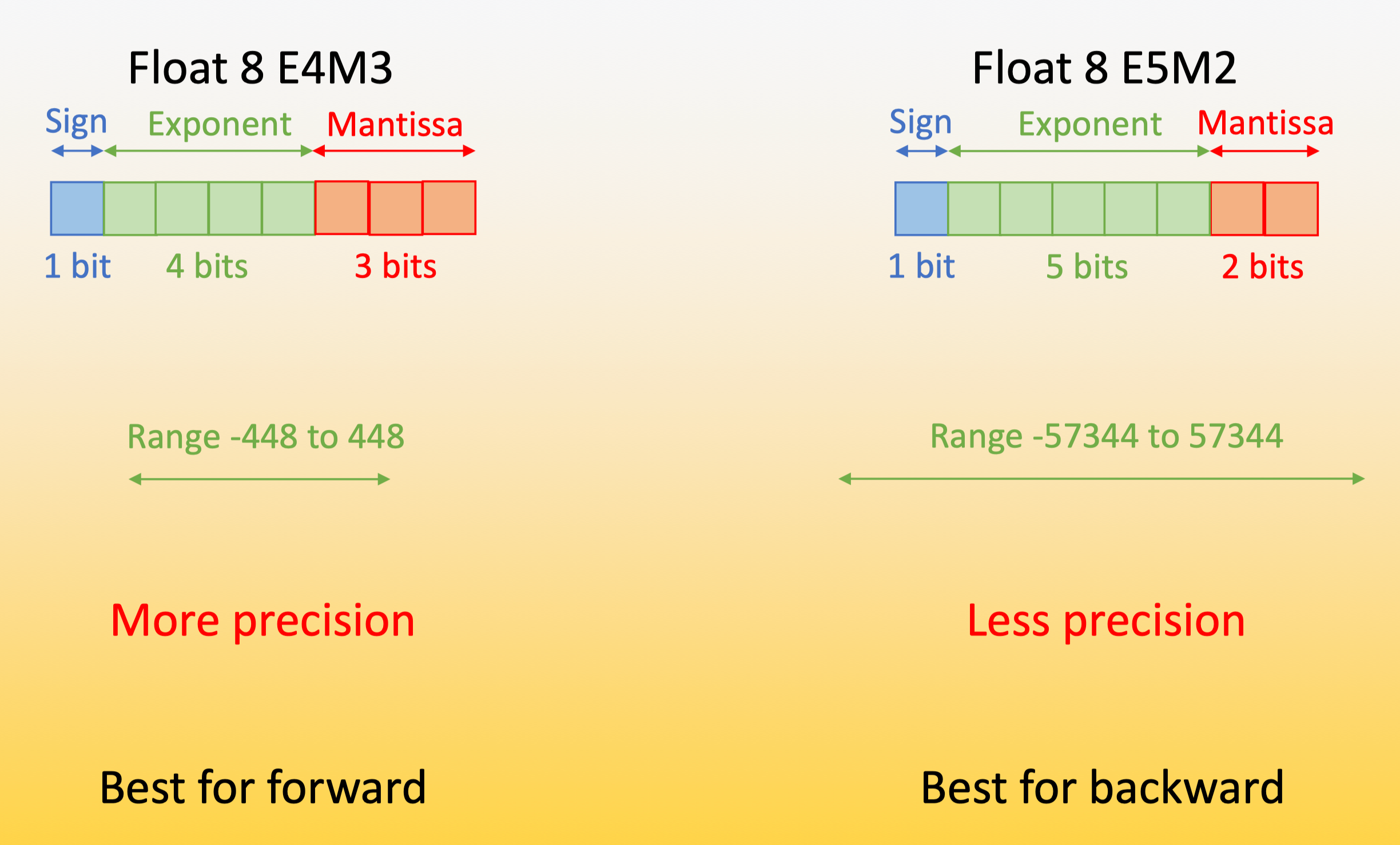
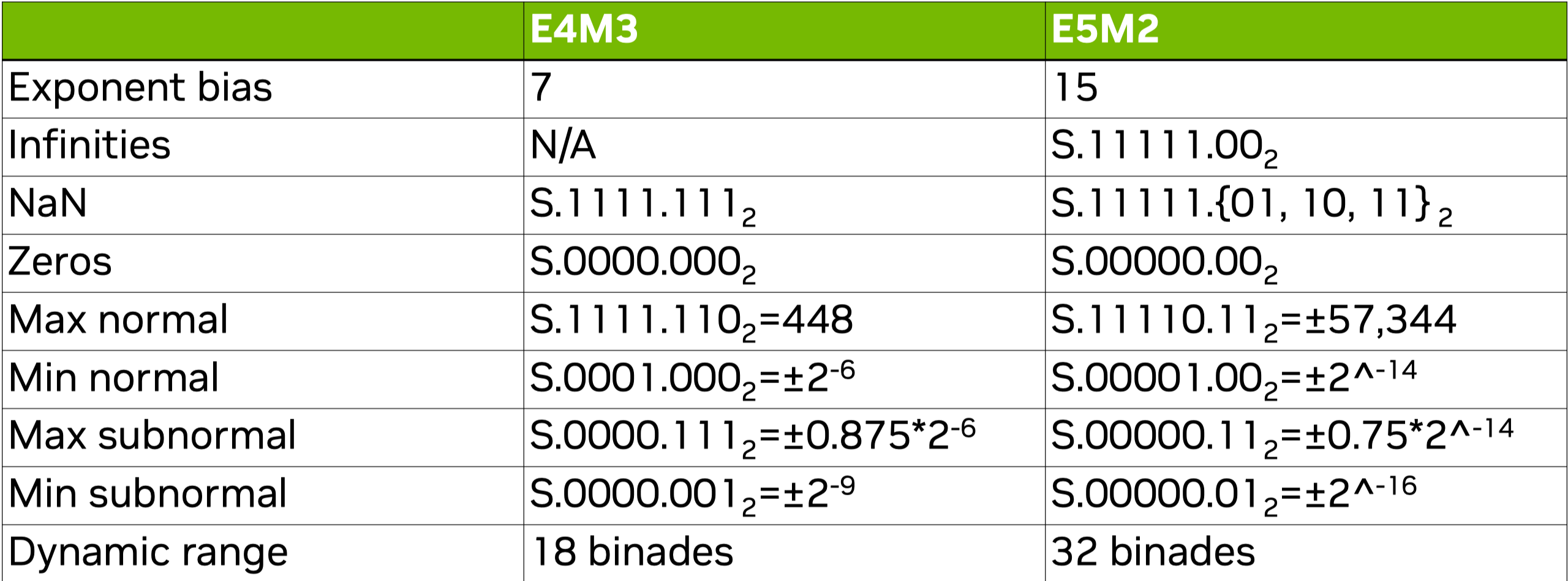
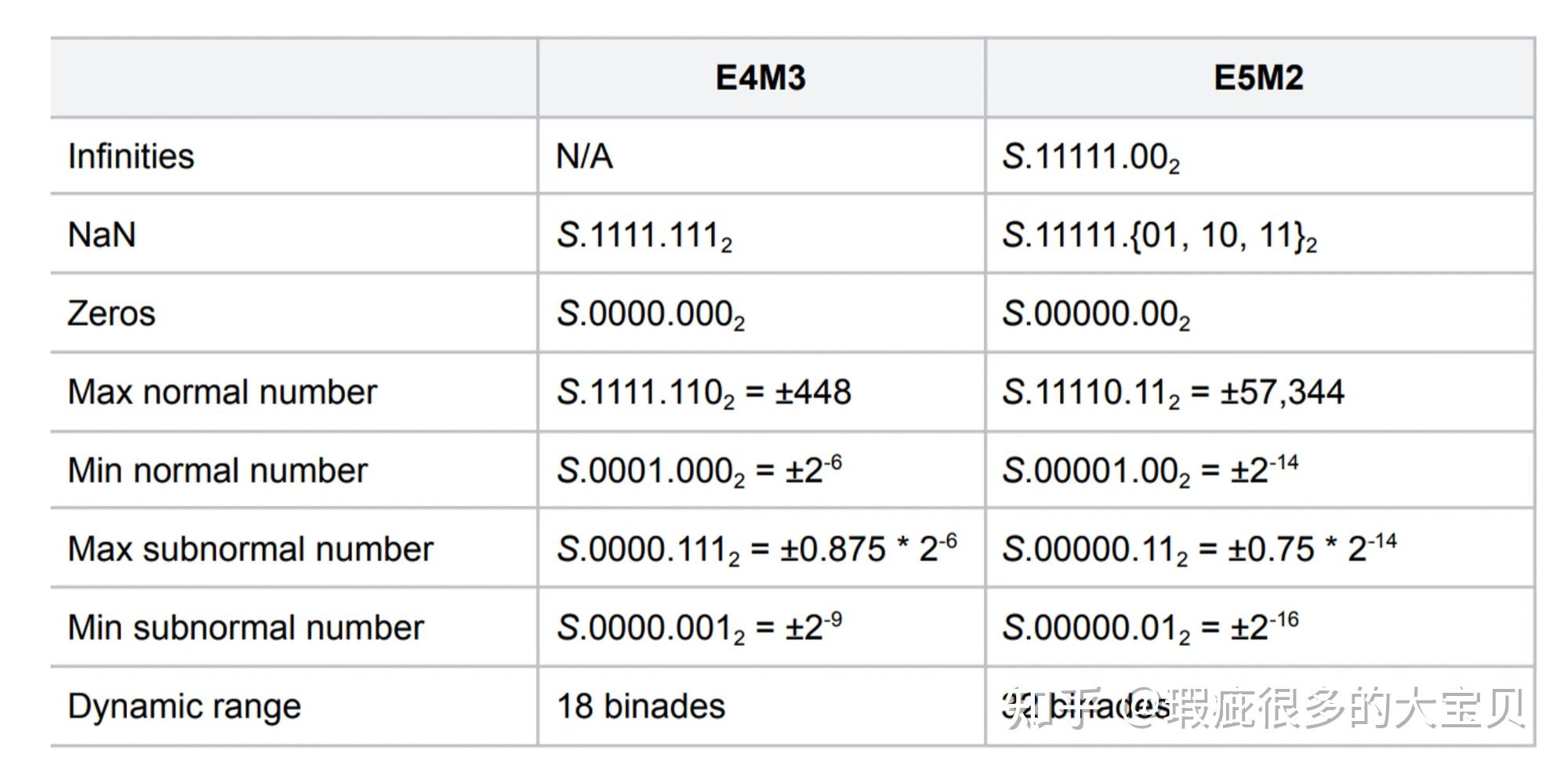
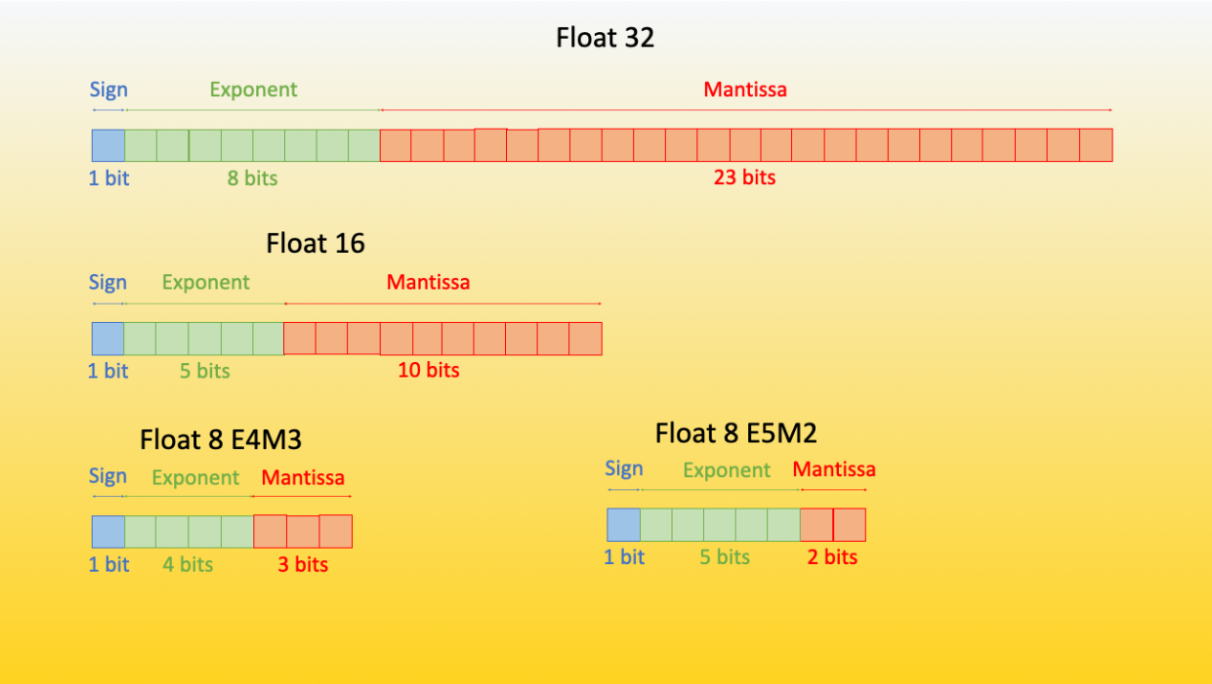
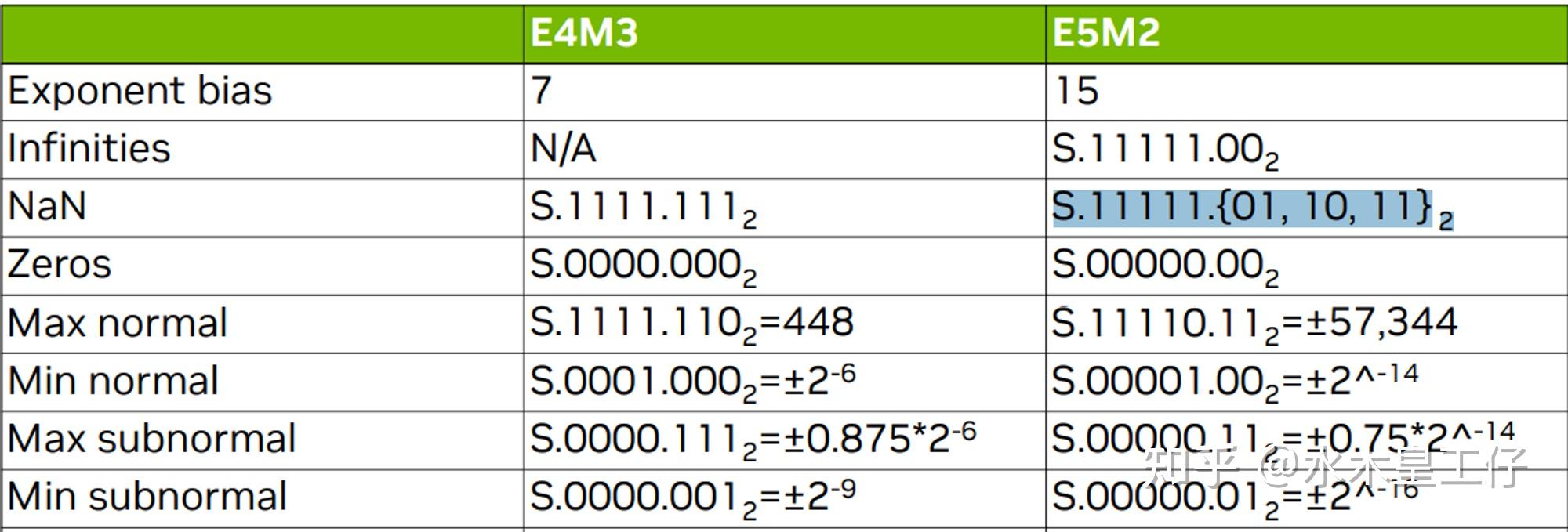
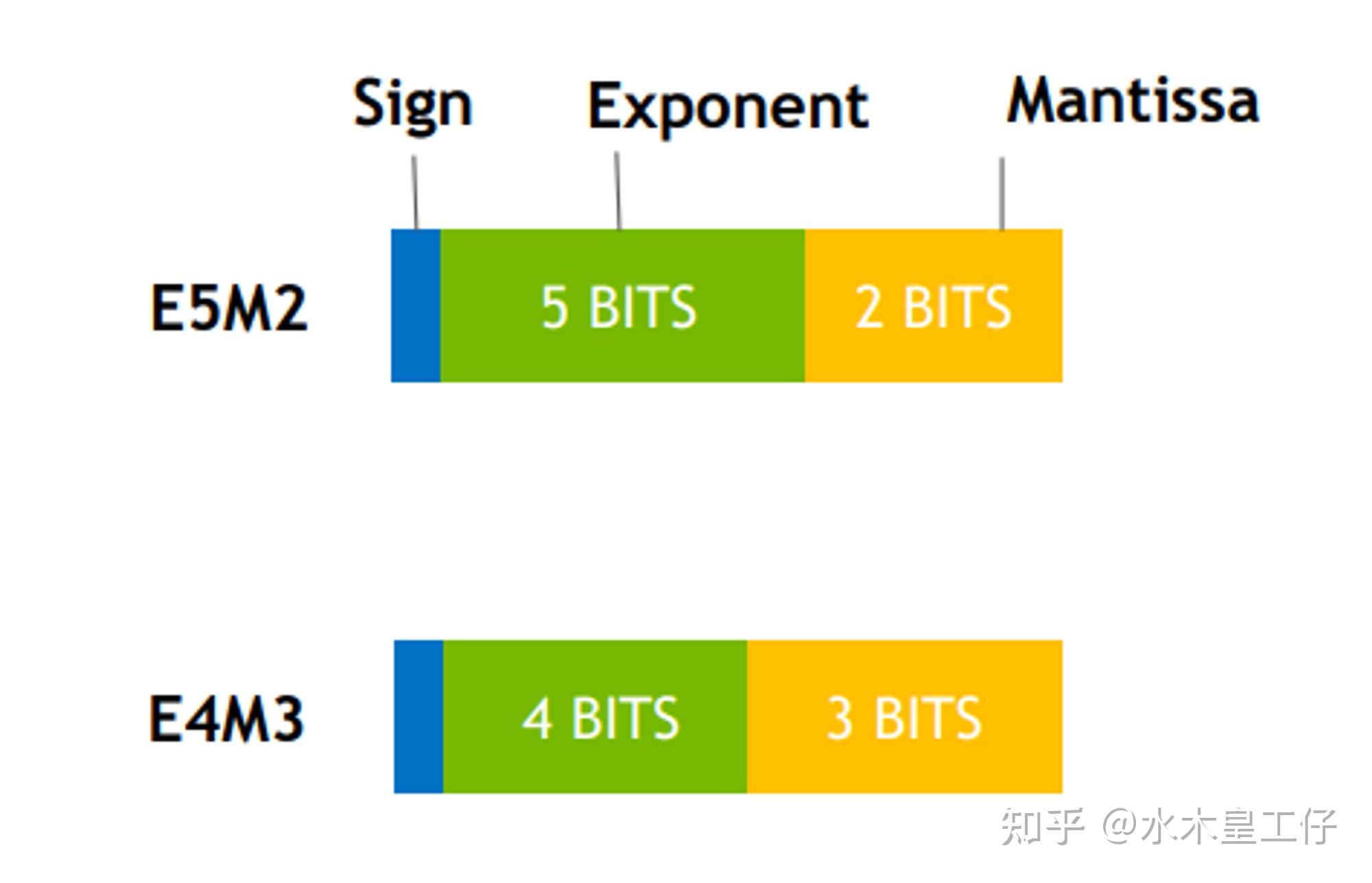
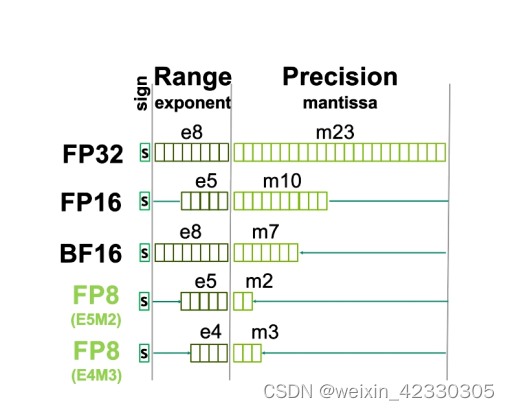
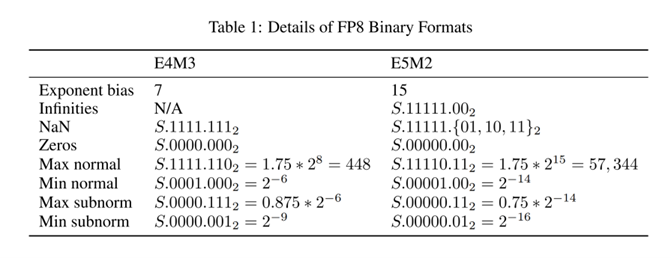
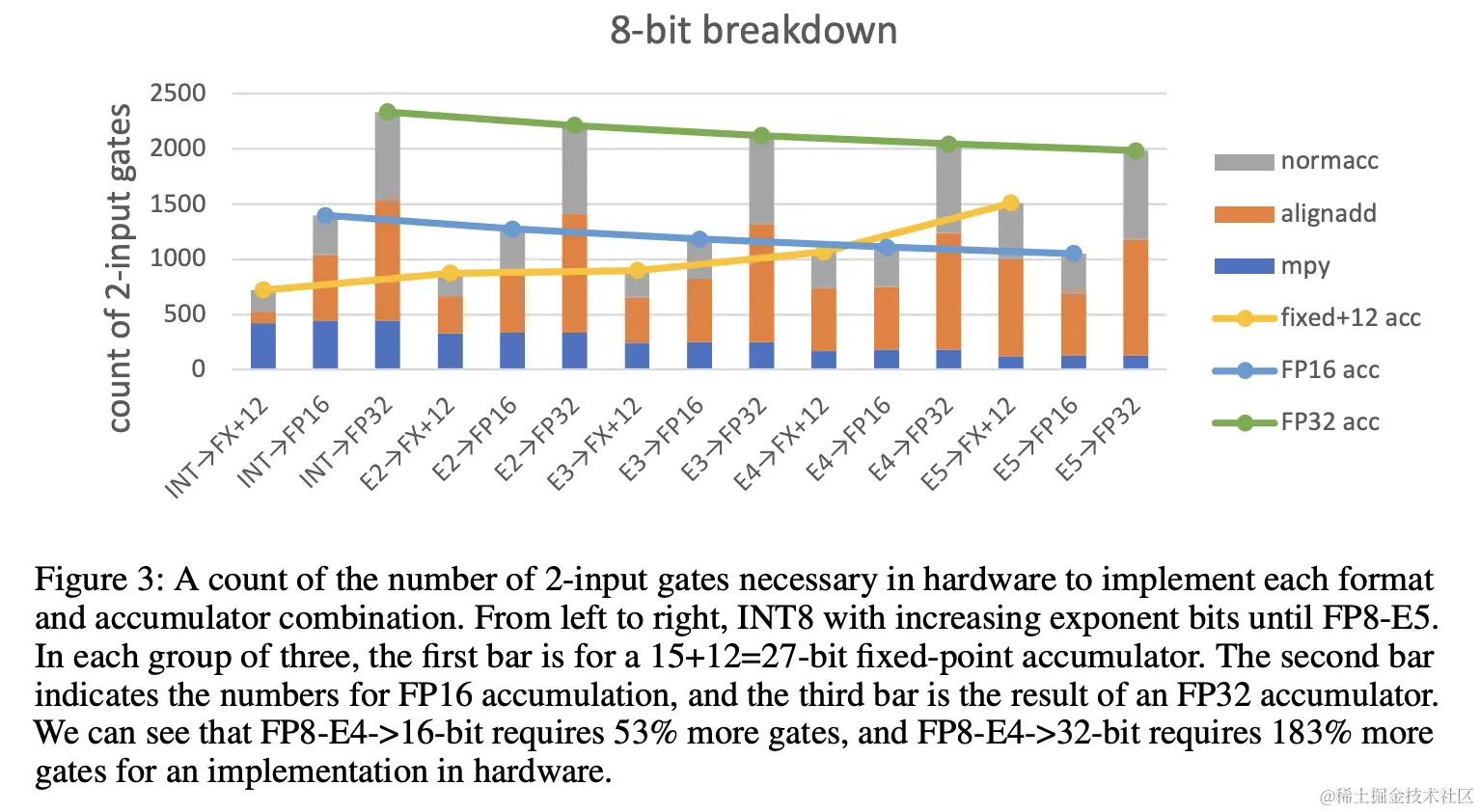
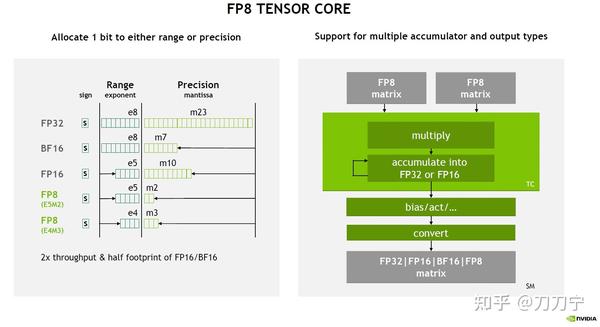
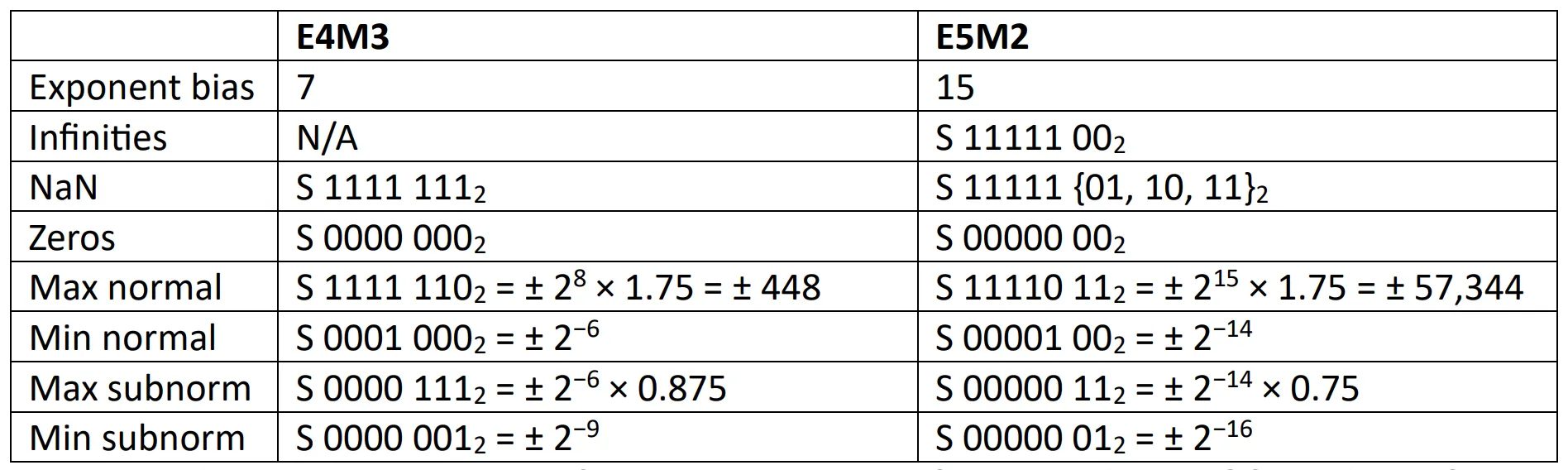
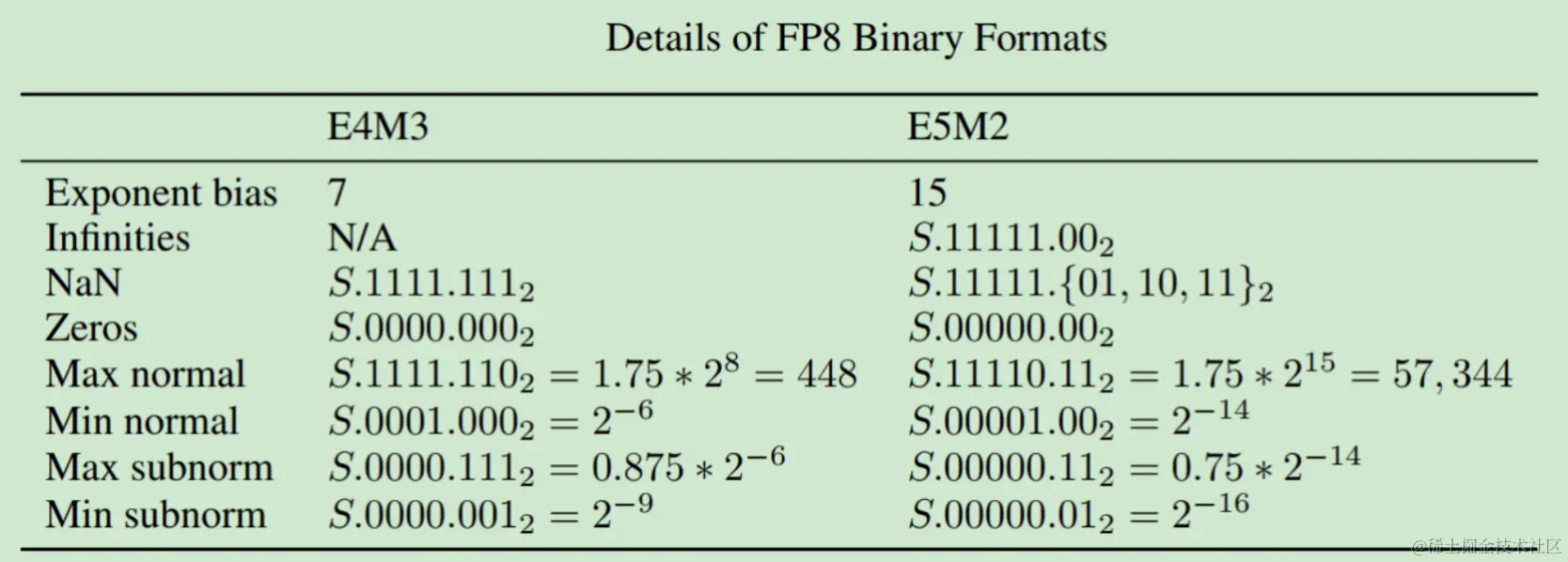
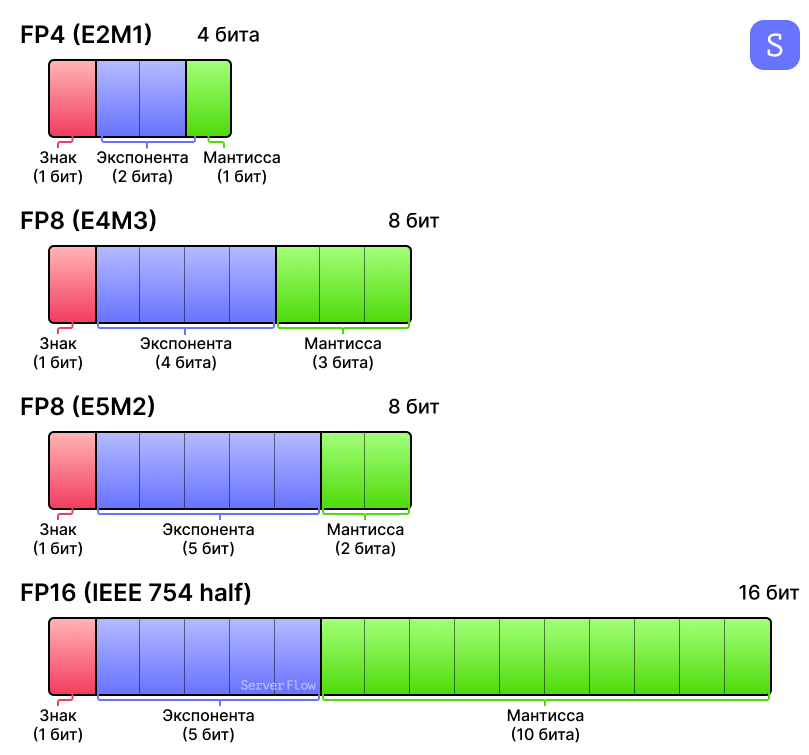
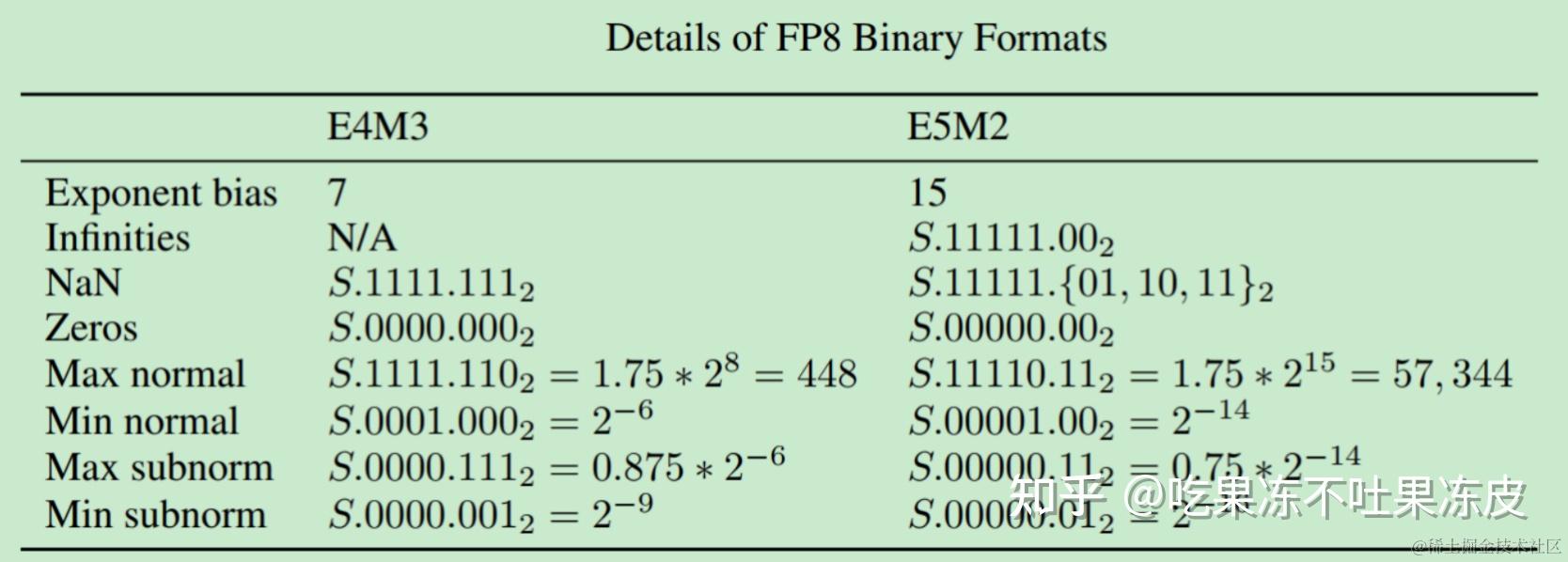
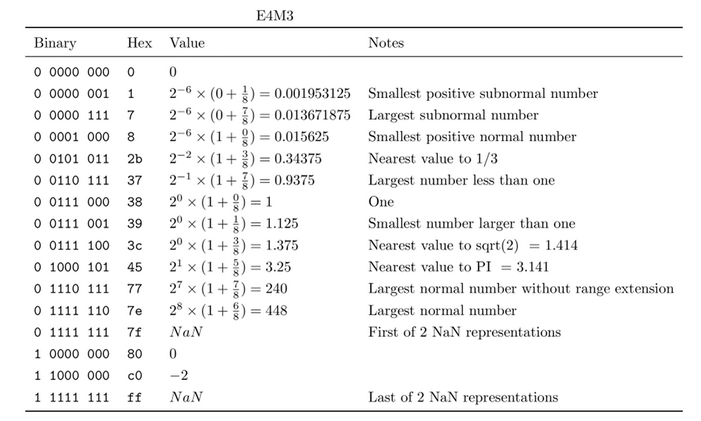
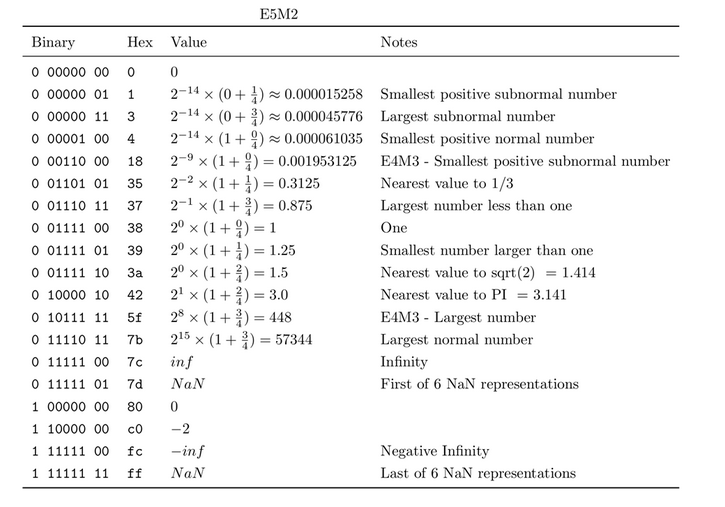
(PDF) FP8 Formats for Deep Learning
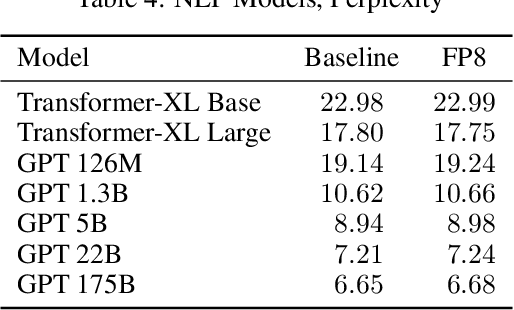
Table 4 from FP8 Formats for Deep Learning | Semantic Scholar
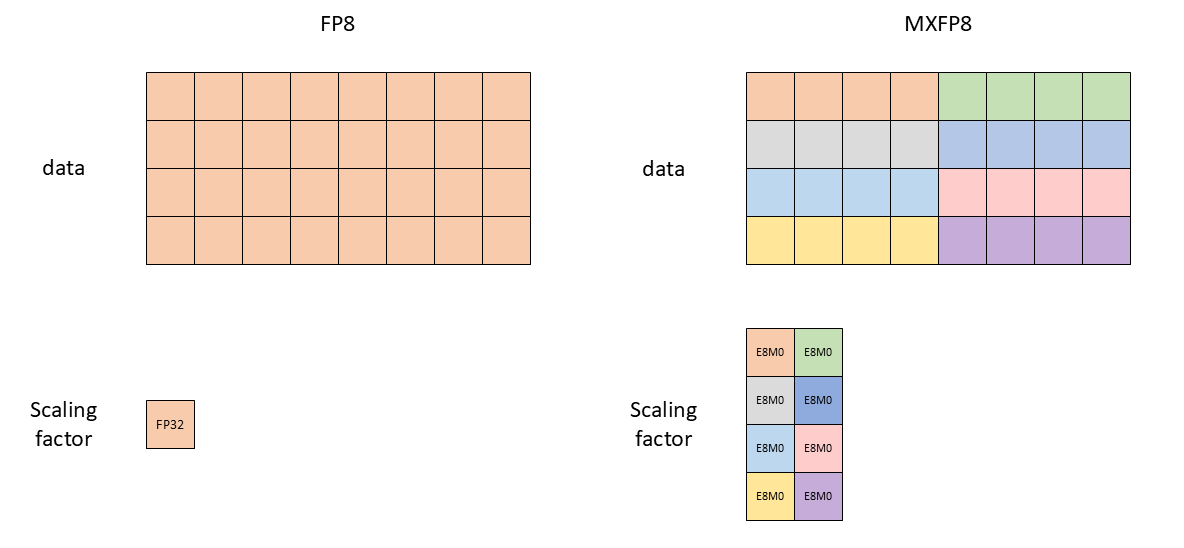
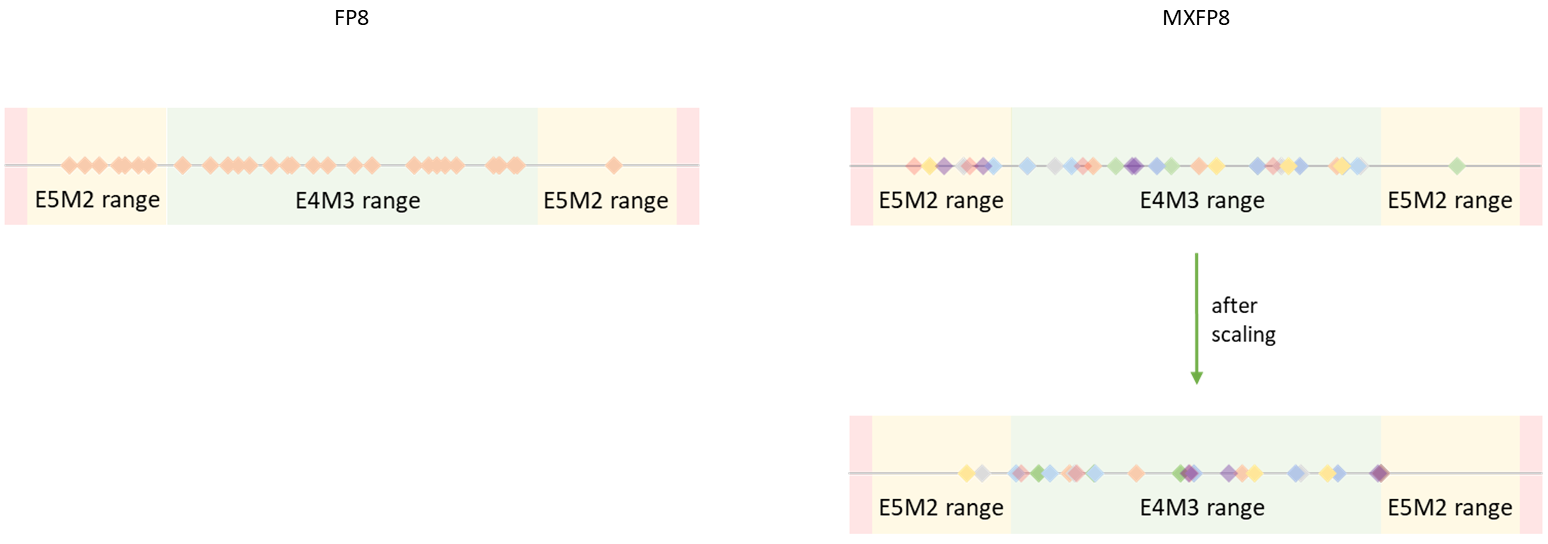
The Road to MX: The Evolution of AI Data Formats (INT8, Bfloat, FP8 ...
[PDF] FP8 Formats for Deep Learning | Semantic Scholar
anton on Twitter: "FP8 is gonna change everything. E4M3 = FP8 variant ...
[2303.17951] FP8 versus INT8 for efficient deep learning inference
FP8 ( 8 bit floating point ). What is it? - YouTube
使用 Triton 内核加速 Llama3 FP8 推理 | PyTorch - PyTorch 深度学习库
Arm Supports FP8: A New 8-bit Floating-point Interchange Format for ...
NVIDIA, Arm, and Intel Publish FP8 Specification for Standardization as ...
浅析 Moe FP8 推理 - 知乎
FP8 trainingを支える技術 1
万字综述:全面梳理 FP8 训练和推理技术-CSDN博客
当谈论 FP8 训练的时候,我们到底在聊什么 - 知乎
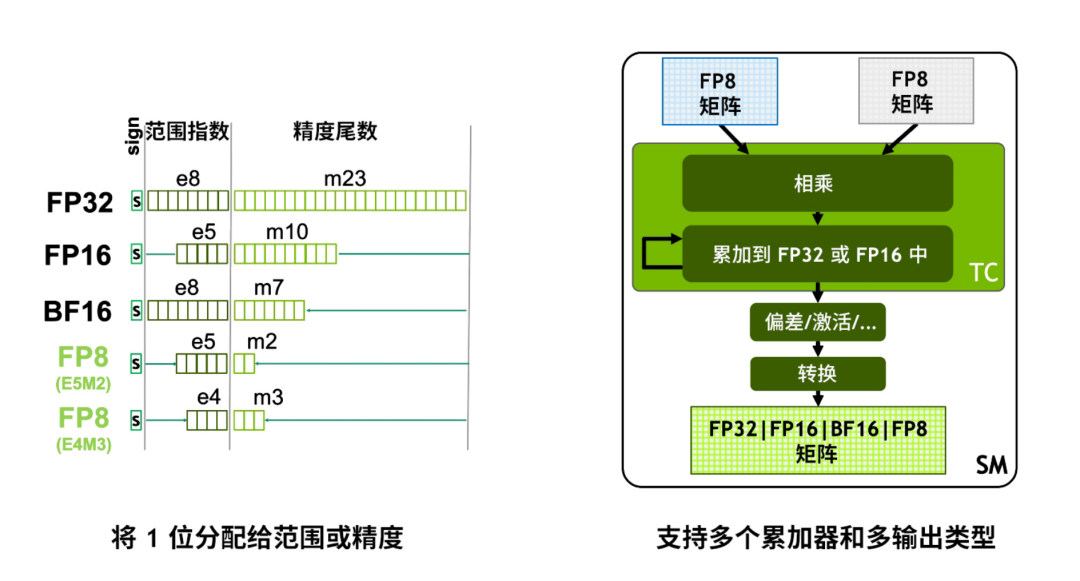
FP8 低精度训练:Transformer Engine 简析 - 53AI-AI知识库|企业AI知识库|大模型知识库|AIHub
FP8 量化-原理、实现与误差分析 - 知乎
FP8 低精度训练:Transformer Engine 简析 - 知乎
Transformer Engine ではじめる FP8 Training (導入編) - NVIDIA 技術ブログ
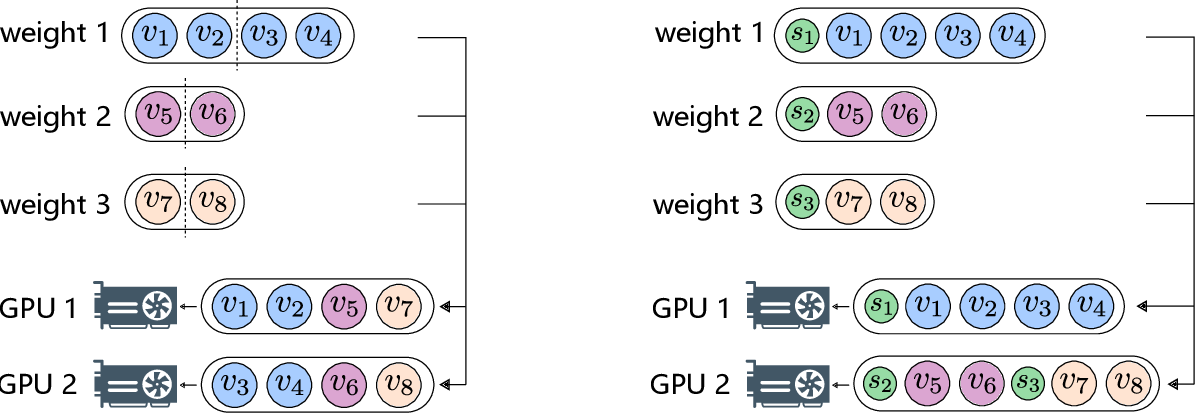
Figure 1 from FP8-LM: Training FP8 Large Language Models | Semantic Scholar
FP8格式理解解析-CSDN博客
Arm Community
Working with ONNX models in float16 and float8 formats - MQL5 Articles
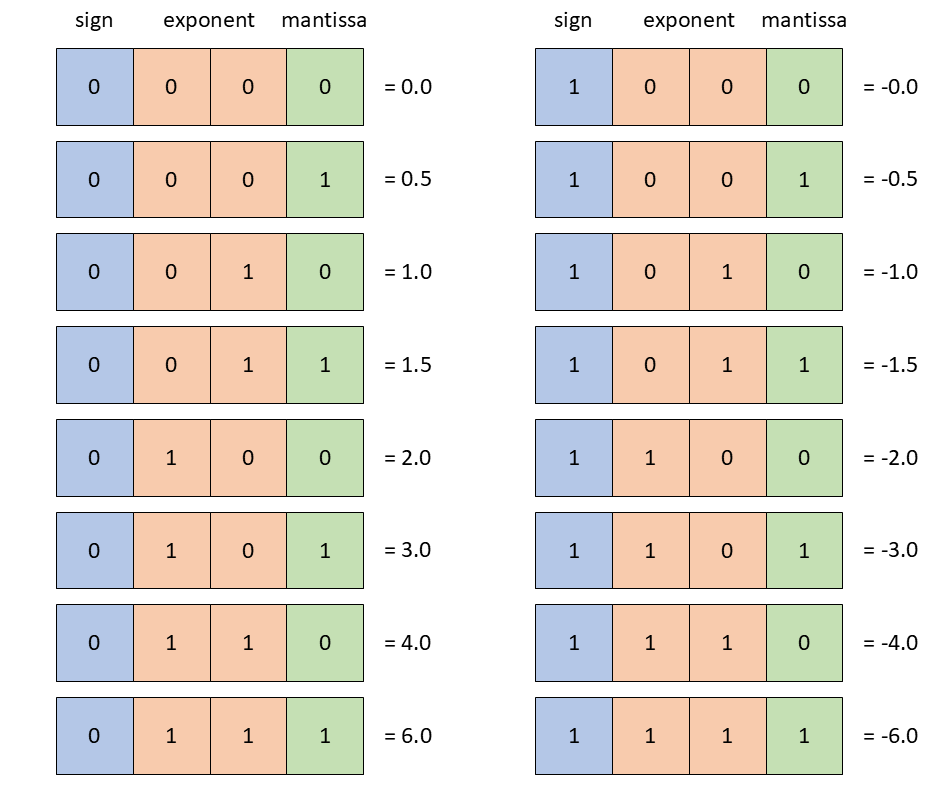
Assembly Language & Computer Architecture Lecture (CS 301)
英伟达、Arm和英特尔公布FP8规格,旨在形成AI交换格式标准-DOIT-数据产业媒体与服务平台
Floating-Point 8: An Introduction to Efficient, Lower-Precision AI ...
大模型量化3 - 张博的博客 - 博客园
FP8: Efficient model inference with 8-bit floating point numbers ...
Floating-point arithmetic for AI inference — hit or miss? | Qualcomm
从DeepSeek V3看FP8训练的挑战 - 知乎
【小白学习笔记】FP8 量化基础 - 英伟达 - 知乎
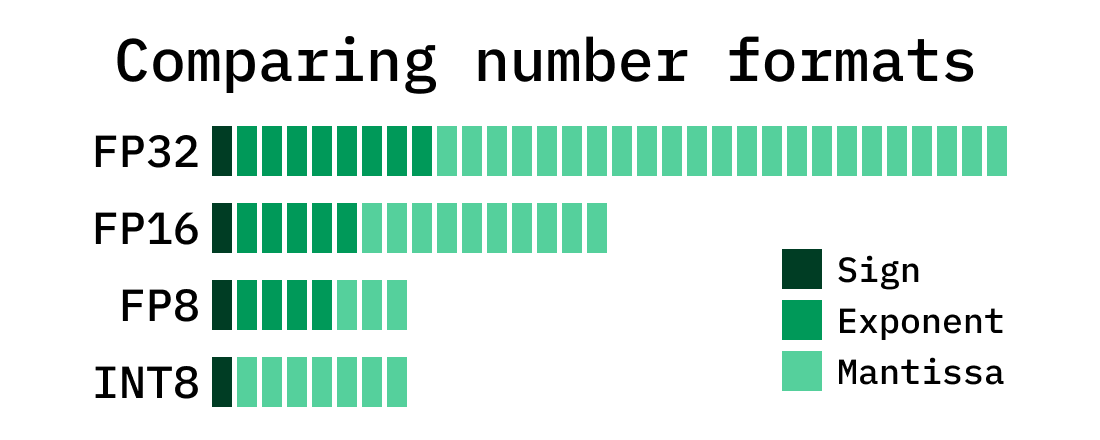
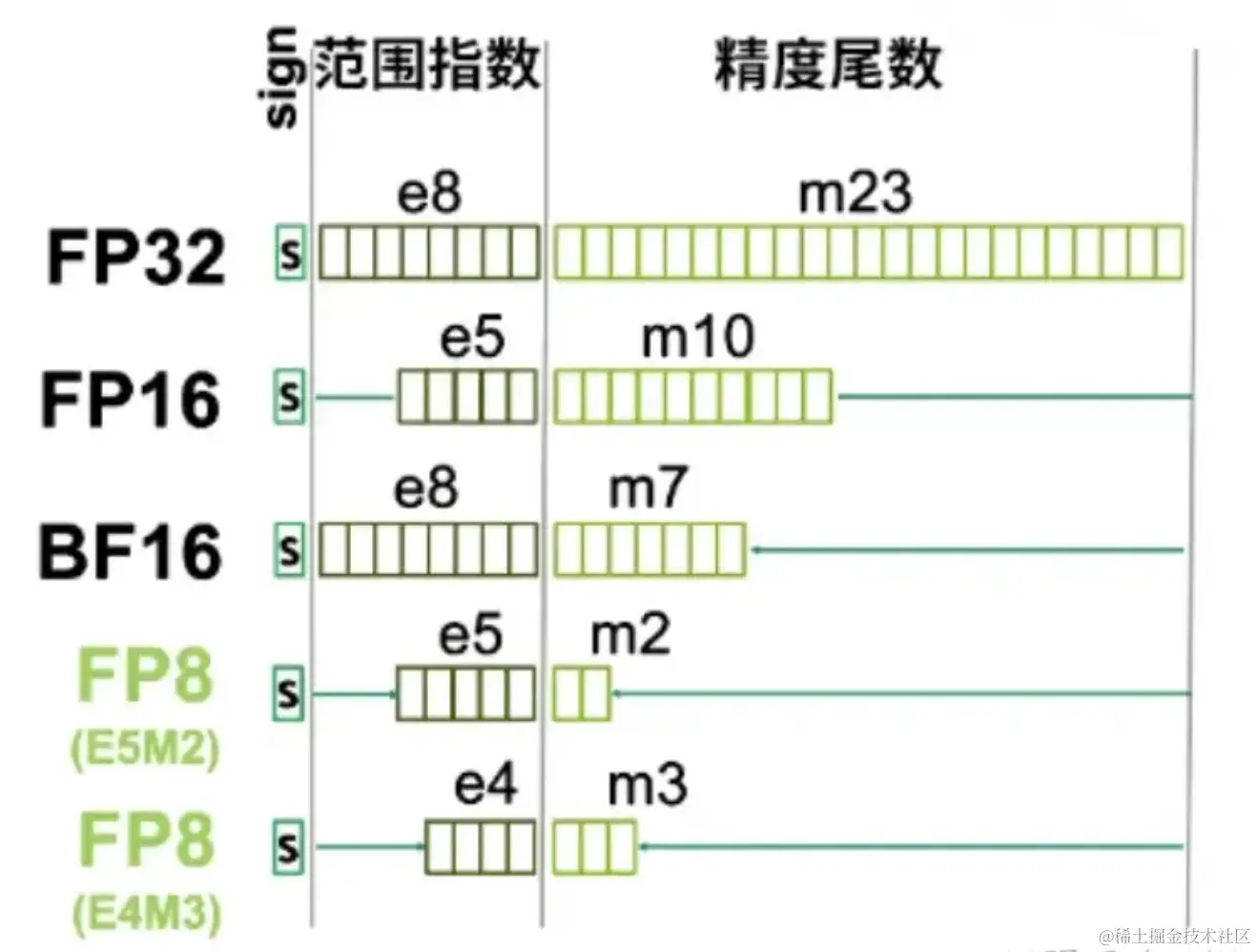
FP64、FP32、FP16、FP8简介-CSDN博客
FP8:前沿精度与性能的新篇章 - NVIDIA 技术博客
大模型量化技术原理:FP8_e4m3-CSDN博客
量化那些事之FP8与LLM-FP4 - 知乎
Unified FP8: Moving Beyond Mixed Precision for Stable and Accelerated ...
DeepSeek V3.1 发布,更令人好奇的是UE8M0 FP8-36氪
从DeepSeek V3看FP8训练的挑战_block scaling-CSDN博客
FP8: архитектура формата E4M3 и E5M2 и его роль в Mixed Precision ...
一文了解模型精度(FP16、FP8等)、所需显存计算以及量化概念_fp8 fp16-CSDN博客
大模型训练之FP8-LLM别让你的H卡白买了:H800的正确打开方式 - 知乎
大模型量化技术原理:FP8 - 知乎
@ImranzamanML on Hugging Face: "Today lets discuss about 32-bit (FP32 ...
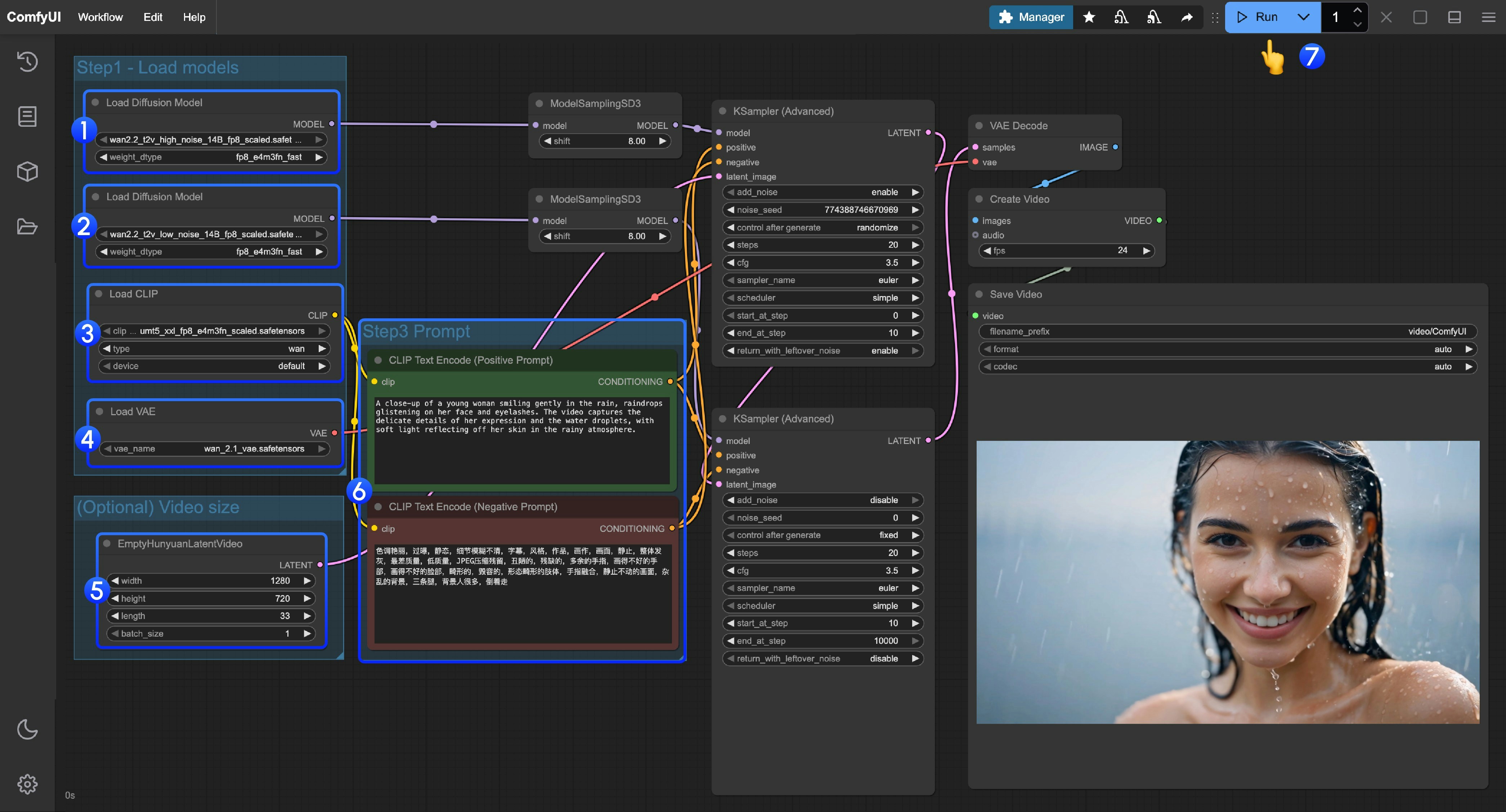
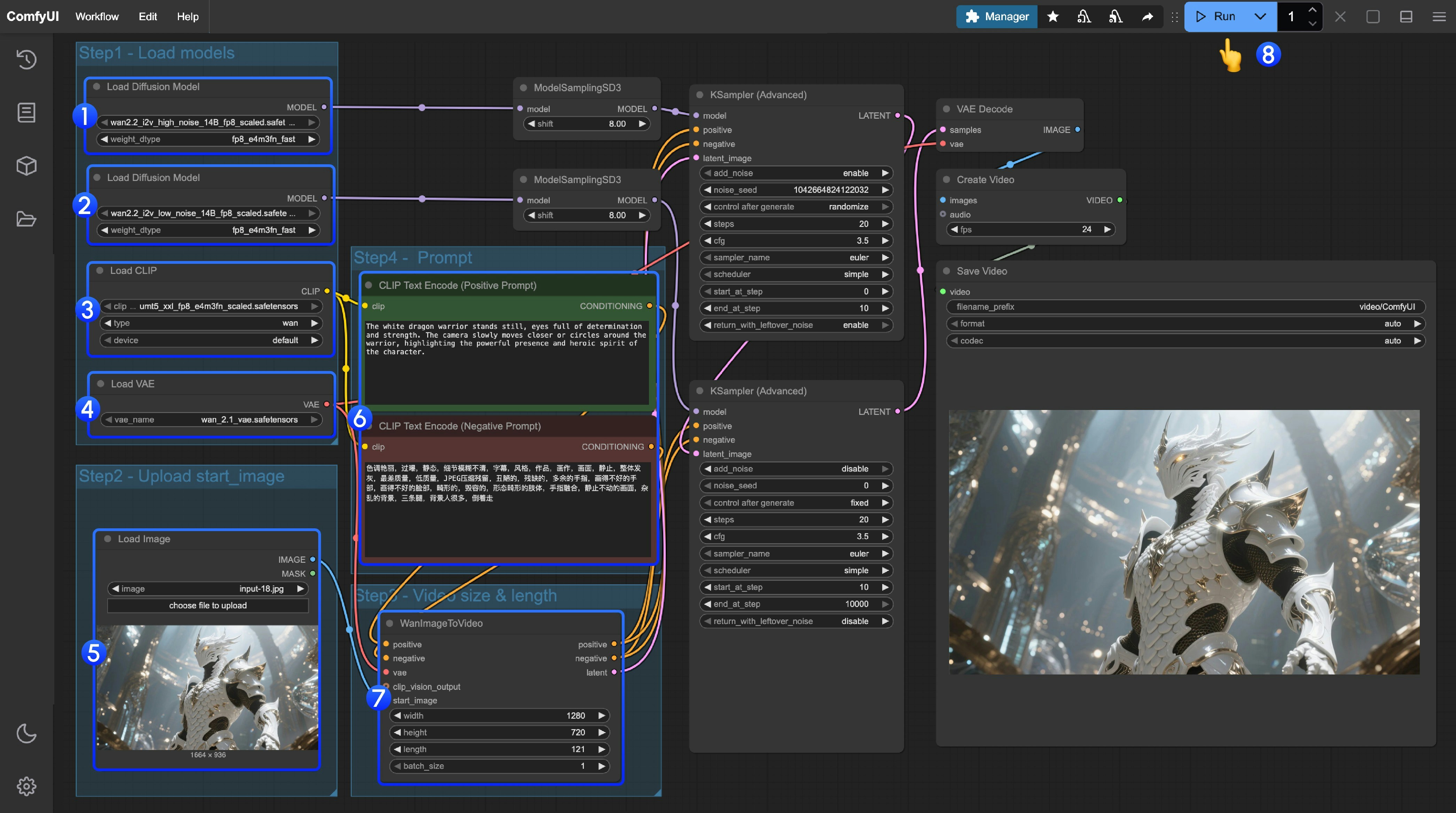
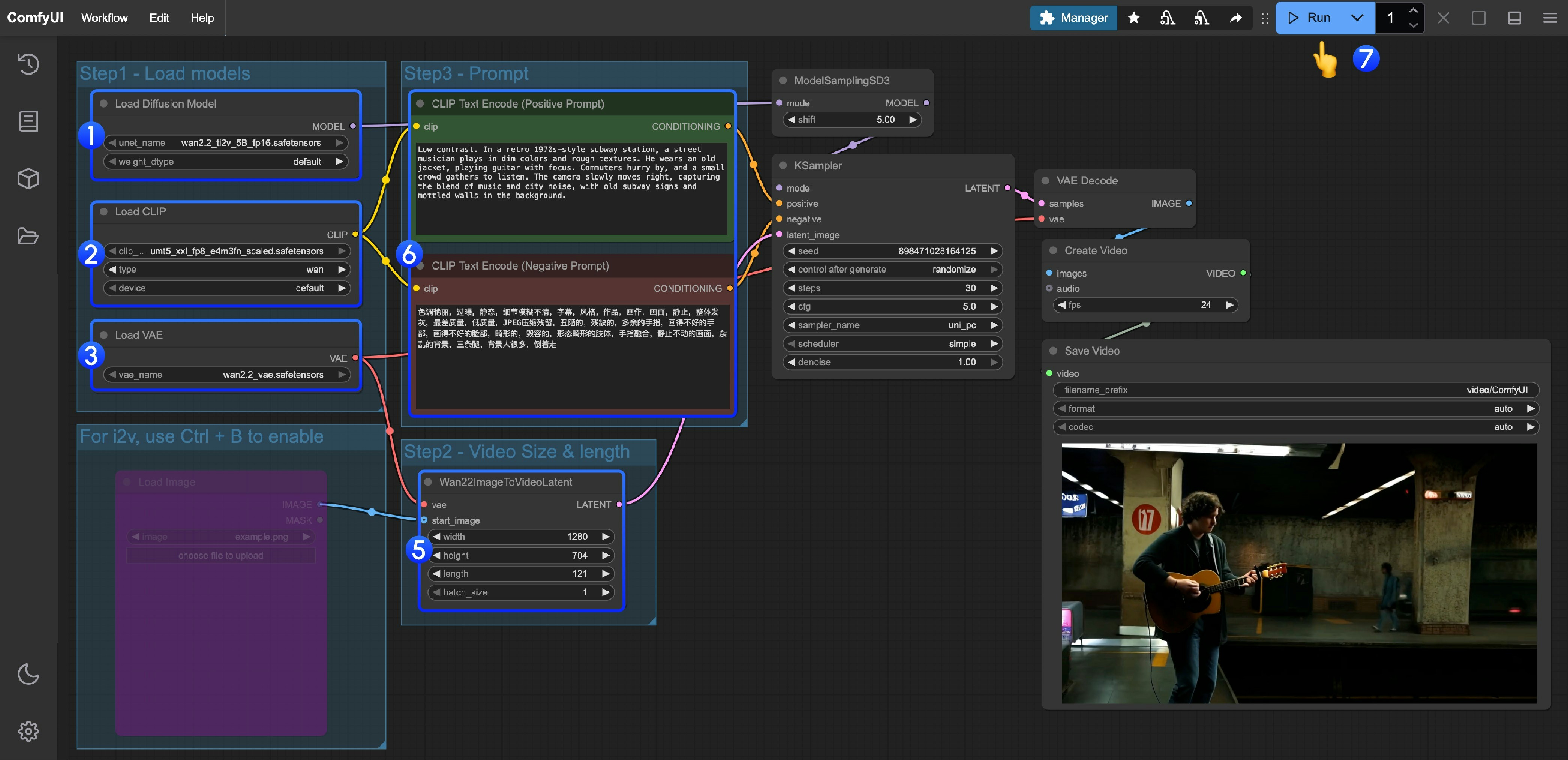
Wan2.2 视频生成ComfyUI 官方原生工作流示例 - ComfyUI
DeepSeek开源V3.1:Agent新纪元开启,哪些企业会受益?-36氪
Oracle adds Nvidia L40S GPU bare metal instances to OCI - DCD
lovedheart/Qwen3.5-4B-FP8 · Hugging Face
Nvidia's B200 boasts 2.2x gain over H100 in MLPerf training
FSR4 INT8 Leak Shows Strong Performance on Older AMD GPUs
Sometimes, Air Is The Only Way For AI Systems To Keep Their Cool
DeepSeek-V3.2系列开源,性能直接对标Gemini-3.0-Pro-36氪
成就DeepSeek奇迹的芯片,敲响英伟达警钟-虎嗅网
Nvidia Finally Admits Why It Shelled Out $20 Billion For Groq
DeepSeek-V4-Flash Benchmarks, FlashRT CUDA Runtime, & V100 LLM ...
Sipeed's new K3 RISC-V SBCs can run 30B-parameter LLMs at 10 tokens per ...
Oracle says it is building a 'zettascale' cloud cluster, with up to ...
替代英伟达,亚马逊AWS已部署超过100万枚自研AI芯片-36氪
China's AI Chip Race: Tech Giants Challenge Nvidia - IEEE Spectrum
单卡1000 TFLOPS,摩尔线程旗舰级计算卡首曝,性能逼近Blackwell-36氪
AMD最强AI芯片全披露,吹响进攻号角-36氪
Inside NVIDIA Blackwell Ultra: The Chip Powering the AI Factory Era ...
Nvidia researchers unlock 4-bit LLM training that matches 8-bit ...
20万字不到1分钱,梁文锋把token价格打骨折了-36氪